This is the first time I have participated in a machine learning competition and my result turned out to be quite good: 66th out of 3303. I used R and an average of two models: glmnet and xgboost with a lot of feature engineering.
The goal of the competition was to predict 6 weeks of daily Sales in 1115 stores located in different parts of Germany based on 2.5 years of historical daily sales.
The first thing I tried after importing data was to convert it into multivariate regular time series and run SVD. The result highlighted several interesting details:
- the majority of stores didn’t have upward or downward trends
- seasonal variation was present but mostly as a Christmas effect
- Sunday was a non-working day in a majority of stores
- there was a strange 2 week cycle which was an effect of running
Promoactions every other week - there were group of stores that didn’t close on Sunday in summer
- some stores had strong yearly pattern
- some stores showed continuous sales increases and other decreases over time
- several stores were missing data from the second half of 2014
I sampled several stores from different groups to check various ideas on them first.
In the beginning my idea was to check how good a single interpretable model could be. There were two simple benchmark models (median and geometric mean) on the competition forum which I used as a starting point.
To validate model quality I implemented time-based cross-validation as described in Forecasting: principles and practice
Interactive visualization helped a lot in identifying features and sources of errors.
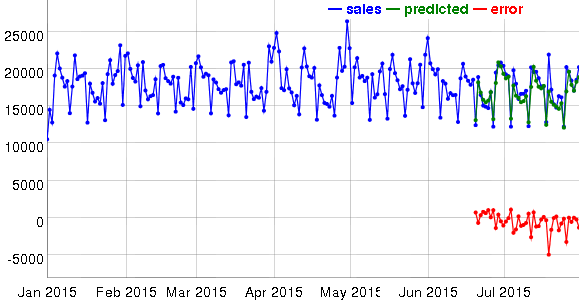
Initially I tried forecast::tbats (a separate model for each store) but the results were quite bad. The influence of non-seasonal factors was big but tbats can’t use external regressors. Next I considered using ARIMA, as it can use regressors, but for long-term forecasts it decays to constant or linear trends. So I continued to evaluate different kinds of linear models. As more and more features were added, the simple linear model started to get worse so I switched to glmnet which is able to select subsets of features.
There was some similarity between Sales and count data so I tried Poisson regression as suggested in Generalized Linear Models in R. This, however, resulted in a larger error in cross-validation than predicting log(Sales) using Gaussian family of generalized linear model.
RMSPE evaluation criteria is asymmetric (see discussion of MAPE) and sensitive to outliers. The typical range for different models and different stores was between 0.08 and 0.25. If a model predicted a sales value of 1000 on a specific day (for example) and the actual sales were 10 because there was an unaccounted holiday, then RMSPE would be equal to 99 for that day which would make an otherwise good model look really bad on average.
The best per store glmnet model scored worse than xgboost, also published on the forum. Tree based regression models don’t extrapolate well because they predict with constant value anything outside their training ranges. The number of stores with long-range trends was small and the majority had quite stable sales over time, so I decided to give xgboost a try and feed it with the same features as I did for linear model (without one-hot encoding for categorical features).
Feature engineering:
- 5 fourier terms generated by
forecast::fourierwith frequency=365; Daysandlog(Days)since the beginning of the training set to capture trends (exponential and linear becauselog(Sales)is predicted);- exponential and linear growth before events or decay after events such as starting
Promoor state holidays (similar to foregen which I discovered later); - binary features which took value 1 for several days before or after events including the start and end of
Promo,Promo2,StateHoliday, and refurbishments; - binary features like
ClosesTomorrow,WasClosedYesterday,WasClosedOnSunday; - day of week, day of month, month number, year as categorical features for xbgoost and n-1 binary features for glmnet (described at https://www.otexts.org/fpp/5/2 ).
For some stores with large error in cross-validation I dropped data before manually selected (by examining Sales time series graphs) changepoints.
The training set contained more stores than were present in the test set. I dropped those extra stores from the training set for xgboost.
I dropped outliers from the training set for glmnet. Outliers were selected by > 2.5 * median absolute residual from lm trained on a small set of features per store.
Initially I used 10 cross-validation folds with 6 weeks length starting from the end of the training set with 2 weeks step (~4.5 months total) but then found that closest to 2014 folds produce large errors for stores with missing in 2014 data. Then I switched to 15 folds with 3 days step to avoid being too close to 2014 which improved predictions for those stores.
RMSPE was quite different for different prediction ranges. For the same store it could go from 0.103 to 0.125 with the same model. It made me think that public leaderboard position is going to change a lot in private leaderboard because they have time based split. It turned out to be true.
Grid search was used to find glmnet alpha parameter. The best alpha was 1 which corresponds to Lasso regularization. Choice of lambda is implemented in cv.glmnet but it uses a standard k-fold cross-validation. I reimplemented it with a time-based cross-validation.
0.985 correction was insignificant on cross-validation (effect was less than standard deviation of RMSPE from different folds) but helped on both private and public leaderboards.
Pairwise feature combinations had positive effect for glmnet on cross-validation but didn’t work on leaderboard.
As a result single per store glmnet model gave prediction error (RMSPE) on private leaderboard 0.11974 (516th place), single all stores xgboost model - 0.11839 (379th), their average - 0.11262 (66th). Complicated ensemble models are good for competitions but in practice it might be better to have 0.007 increase in error and simple interpretable model.
Source code is available at github.com/mabrek/kaggle-rossman-store-sales